

Custom Entity Extraction in RASA
RASA [1] stellt ein mächtiges Werkzeug zur Entwicklung professioneller Chatbot-Lösungen dar. Ein wichtiges Mittel zur präziseren Bearbeitung von Anfragen ist dabei die Extraktion sogenannter Entitäten. Extraktoren können dazu verwendet werden, um wichtige Informationen wie beispielsweise Namen oder den Zweck der Eingabe aus Texten herauszufiltern.
Nachfolgend steht ein kleiner Beispielsatz, in dem ein {Vorname}, ein {Nachname} und der Typ der Anfrage als {Telefon} erkannt wurde:
„Wie lautet die Telefonnummer{Telefon} von Max{Vorname} Mustermann{Nachname}?“.
Entitäten können individuelle Mappings zwischen dem jeweiligen Entitätentyp und dazu passenden Schlagwörtern enthalten. Beispielsweise könnte die Entität {Telefon} an die Schlagwörter [„Telefonnummer“, „Handynummer“, „Nummer“, „Anruf“, …] geknüpft werden.
RASA stellt verschiedene vordefinierte Extraktoren zur Verfügung, mit deren Hilfe Entitäten aus Eingaben extrahiert werden können. Diese basieren auf den unterschiedlichsten Mechanismen. Beispielsweise nutzt der „CRFEntityExtractor“ Conditional Random Fields (CRF), um Entitäten zu erkennen. Dieses Verfahren soll hier jedoch nicht näher behandelt werden soll. Eine vollständige Liste der RASA-eigenen Standardextraktoren ist unter [2] hinterlegt. Nach unseren Erfahrungen können die Standardextraktoren vor allem glänzen, sofern es sich bei den Schlagwortlisten um wohldefinierte Wortgruppen handelt. Falls ein Entitätentyp unterschiedliche und einzigartige Wörter enthält, stoßen RASAs Standardextraktoren schnell an ihre Grenzen, da keine präzisen Modelle der Strukturen aufgebaut werden können. Ein Beispiel hierfür stellt die Extraktion von Namen dar: Hier konnte RASA in einigen Tests die lange Liste der Namen (> 2000), die wir aus Eingaben extrahieren wollten, unter Verwendung des besagten „CRFEntityExtractors“ nur mäßig gut verarbeiten: Viele Namen wurden nicht erkannt, Vornamen wurden als Nachnamen erkannt und umgekehrt.
Aus diesem Grund möchten wir Ihnen in den folgenden Abschnitten eine Methode vorstellen, mit der Sie Ihre eigenen, individuellen Extraktoren für RASA schreiben und in Ihr bestehendes Projekt integrieren können. Dafür hat das ESC eigene Extraktoren unter MIT-Lizenz auf GitHub [3] veröffentlicht. Diese verwenden einen einfachen Fuzzy Matching-Ansatz, um Entitäten in Texten zu erkennen. Dabei wird geprüft, wie sehr sich zwei Eingaben ähneln. Unser Ansatz kann leicht durch komplexere Matching-Algorithmen erweitert werden.
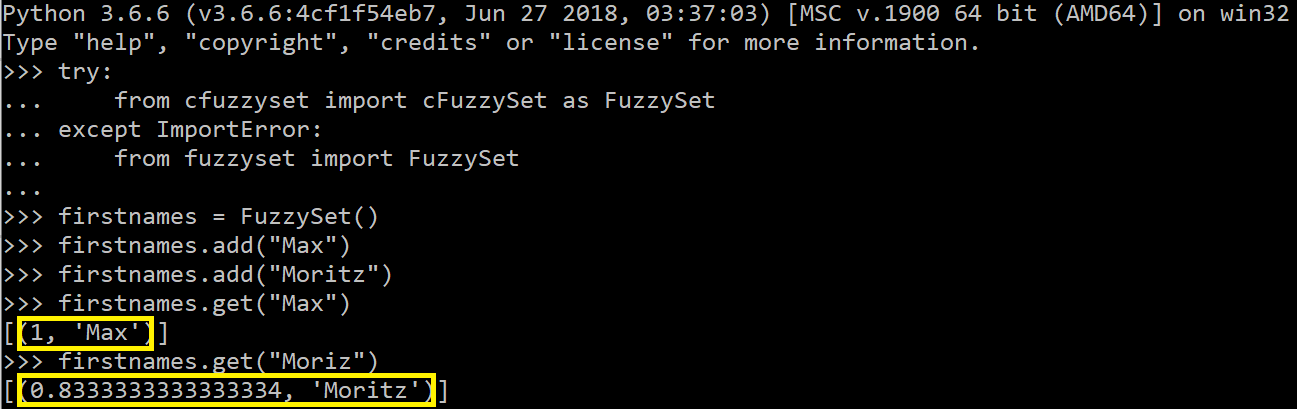
Im folgenden Beispiel wurden die beiden Namen „Max“ und „Moritz“ dem FuzzySet „firstnames“ hinzugefügt. Dadurch kann mithilfe von „get“ geprüft werden, wie sehr eine Eingabe den Wörtern des FuzzySets ähnelt. Beispielsweise hat die Eingabe „Max“ eine 100%-ige Übereinstimmung zum Wort „Max“ in „firstnames“. In die Eingabe „Moriz“ hat sich jedoch ein Tippfehler eingeschlichen, sodass lediglich fünf der Buchstaben mit dem FuzzySet-Wort „Moritz“ übereinstimmen. Damit liegt deren Übereinstimmung bei ca. 83%. Die zu filternden Entität-Schlagwortlisten-Paare können beispielsweise in einer Datenbank (database_entity_extractor [3]) oder einer .json-Datei (simple_entity_extractor [3]) hinterlegt werden. Für den folgenden Abschnitt wäre es fürs bessere Verständnis hilfreich, den database_entity_extractor [3] parallel zu öffnen und die Informationen nachzuvollziehen. Dieser verwendet eine Datenbank mit Vor- und Nachnamen als Entitäten.
Jeder individuelle Extraktor muss von der RASA-eigenen Oberklasse EntityExtractor erben. Die wesentlichen Funktionen, die in von unseren Templates verwendet werden, sind __init__ und process. Diese entsprechen den Funktionsdefinitionen, die von den offiziellen RASA-Extraktoren verwendeten werden.
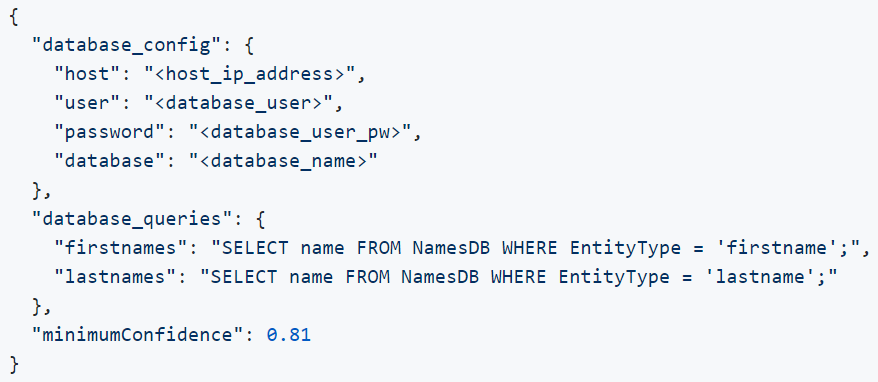
__init__ stellt den Konstruktor der Klasse dar und ist somit für deren korrekte Initialisierung verantwortlich. Wichtige Parameter werden anhand der übergebenen parameters gesetzt. Im Fall des database_entity_extractors werden hiermit Verbindungsinformationen der verwendeten Entitätsdatenbank, Zugriffsqueries und die minimale Konfidenz zwischen Eingabe und Entitäten an den Extraktor übergeben:
Die Funktion process stellt die ausführende Methode des Extraktors dar. Sie wird automatisch aufgerufen, sobald eine Anfrage an den Extraktor gestellt wird, und liefert die in der Eingabe gefundenen Entitäten sowie deren Position zurück. Beispielsweise liefert unser individueller database_entity_extractor auf die Frage „Wer ist Frau Müller?“ das folgende Ergebnis zurück:
"entities": [ { "start": 13, "end": 19, "value": "Müller", "confidence": 1, "entity": "lastname", "extractor": "DatabaseEntityExtractor" }]Dabei wurde darauf geachtet, dass das für RASA übliche Schema zur Darstellung einer Entität in der Rückgabe beibehalten wurde: Eine gefundene Entität hat die Eigenschaften start und end (Positionen des ersten bzw. letzten Buchstabens), value (das gefundene Wort), confidence (die Wahrscheinlichkeit, dass es sich bei dem gefundenen Wort tatsächlich um eine Entität des genannten Typs handelt) und entity (Typ der Entität). Somit wurde der Name Müller an der dreizehnten Stelle in der Anfrage gefunden und korrekt als Nachname erkannt. Damit eigene Extraktoren in RASA verwendet werden können, muss ihr Speicherort im Python-Path des RASA-Servers hinterlegt werden. Falls ein Dockercontainer verwendet wird, kann dies einfach durch das Hinzufügen der Zeile
ENV PYTHONPATH "${PYTHONPATH}:/path/to/my/extractor"zum Dockerfile bewerkstelligt werden.
Neben den beiden bereits angesprochenen Extraktoren database_entity_extractor und simple_entity_extractor haben wir noch eine dritte Implementierung in unserem GitHub [3] hinterlegt: den luis_entity_extractor. Dieser ermöglicht die Verwendung unseres Fuzzy Matching-Ansatzes auf exportierten LUIS-Modellen [4]. Hierfür werden die List-Entitäten [5], welche aus LUIS bekannt sind, verwendet. Zusammen mit den von RASA bereitgestellten Migrationsmechanismen [6] ermöglicht dies die einfache Migration von LUIS zu RASA und damit von einer cloudbasierten Lösung direkt zu einer Offline-Lösung.
[1] https://rasa.com/
[2] https://rasa.com/docs/rasa/nlu/entity-extraction/
[3] https://github.com/ESCdeGmbH/rasa-custom-entity-extraction
[5] https://docs.microsoft.com/de-de/azure/cognitive-services/luis/reference-entity-list
[6] https://rasa.com/docs/rasa/migrate-from/microsoft-luis-to-rasa/
MEHR BLOG-KATEGORIEN
- ASP.NET
- Active Directory
- Administration Tools
- Allgemein
- Backup
- ChatBots
- Configuration Manager
- DNS
- Data Protection Manager
- Deployment
- Endpoint Protection
- Exchange Server
- Gruppenrichtlinien
- Hyper-V
- Intune
- Konferenz
- Künstliche Intelligenz
- Linux
- Microsoft Office
- Microsoft Teams
- Office 365
- Office Web App Server
- Powershell
- Remote Desktop Server
- Remote Server
- SQL Server
- Sharepoint Server
- Sicherheit
- System Center
- Training
- Verschlüsselung
- Virtual Machine Manager
- Visual Studio
- WSUS
- Windows 10
- Windows 8
- Windows Azure
- Windows Client
- Windows Server
- Windows Server 2012
- Windows Server 2012R2
- Windows Server 2016
- Windows Server 2019
- Windows Server 2022
- Zertifikate











