

Microsoft SQL Server 2017 – Neuerungen im Vergleich zur Vorversion 2016
Der Microsoft SQL Server ist im Vergleich zu den großen Konkurrenten, wie beispielsweise dem Oracle SQL Server noch eine recht junge Technologie. Aus diesem Grund entwickelt sich der Microsoft SQL Server schnell weiter. Dies geschieht durch das Hinzufügen oder Entfernen von neuen beziehungsweise alten Funktionen, sowie durch die Optimierung bereits vorhandener Funktionen.
Das neuste Mitglied der Reihe der Microsoft SQL Server trägt den Namen „Microsoft SQL Server 2017“ und besitzt das Kompatibilitätslevel 140. Nachdem mit 2016 viele neue Funktionen zu SQL Server hinzugefügt worden sind, trägt die neuste Version vor allen Dingen dazu bei, die Sicherheits- und Performanceaspekte der SQL Server zu verbessern. Im Folgenden werde ich auf einige wichtige Neuerungen des SQL Servers 2017 eingehen. Hierbei werde ich mich explizit auf das Adaptive Query Processing, Adaptive Joins und die Automatic Database Optimization konzentrieren.
Die Optimierung der Ausführungszeiten von Queries ist ein wichtiges Forschungsgebiet im Bereich der Datenbankentwicklung. Bis 2016 wurden Queries im SQL Server standardmäßig folgendermaßen abgearbeitet: Der sogenannte Abfrageoptimierer generiert zunächst verschiedene Ausführungspläne für die Query und schätzt den jeweiligen Aufwand anhand von diveresen Statistiken. Daraufhin wählt er den Plan mit dem geringsten Aufwand aus, der daraufhin ausgeführt wird. Dieses Vorgehen ist jedoch nicht immer optimal. Es kann zu verschiedenen Problemen kommen, wie beispielsweise Spill Data (Server benötigt mehr Ressourcen als gedacht) oder Parameter Sniffing (Server schätzt Anzahl der zurückgegebenen Zeilen falsch ein). Diese Probleme werden mithilfe des sogenannten Adaptive Query Processings umgangen. Dieses Verfahren optimiert die Schätzung für eine spätere, erneute Ausführung der Abfrage. Um dies zu gewährleisten wertet SQL Server 2017 den Speicherverbrauch, sowie verwendeten Parameter der ersten Anfrage aus, da das Ausführen der Query je nach Parameter unterschiedlich viele Ressourcen benötigen kann. Das Adaptive Query Processing ermöglicht somit eine enorme Leistungssteigerung durch parametersensitive Szenarien und das speicherabhängige Feedback.
Ein kleines Beispiel für eine solche Optimierung ist unter [1] zu finden. In den folgenden Abbildungen kann man den für die Ausführung einer Beispielquery benötigten Speicherverbrauch sehen (oben: 1. Ausführung, 88 Sekunden, Überlauf; unten: 2. Ausführung, 1 Sekunde, kein Überlauf):
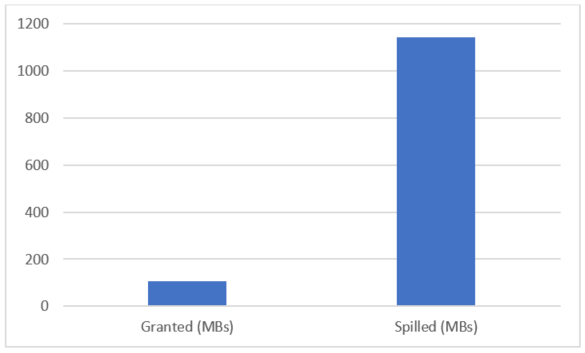
1. Ausführung, 88 Sekunden, Überlauf

2. Ausführung, 1 Sekunde, kein Überlauf
Das Adaptive Query Processing sollte durch Erhöhen des Kompatibilitätslevels der Datenbank auf 140 automatisch aktiviert werden.
Ein weiteres wichtiges Mittel zur Optimierung der Queryleistung sind die sogenannten Adaptive Joins. Diese kombinieren die beiden Join-Typen Nested-Loop-Join und Hashjoin, um so die Join-Geschwindigkeit in Queries, gerade bei stark schwankenden Tabellengrößen, bei denen eine Indizierung weniger effizient ist, zu verbessern. Dazu muss ein Schwellwert für die Zeilenzahl definiert werden, bis zum dem Nested-Loop-Joins verwendet werden. Nach Überschreiten des Schwellwerts werden Hashjoins angewendet. Das folgende Diagramm (aus [1]) veranschaulicht die korrekte Wahl eines Schwellwerts exemplarisch. Dieser Wert hängt von der verwendeten Datenbank ab und muss durch diverse Tests gefunden werden.
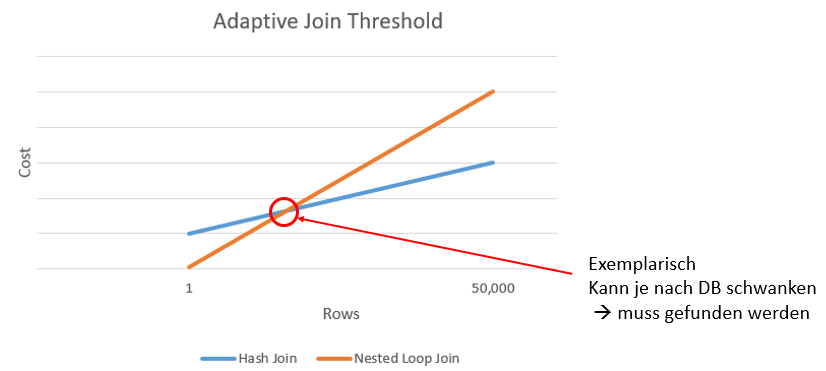
Die Adaptive Joins sollten durch Erhöhen des Kompatibilitätslevels der Datenbank auf 140 automatisch aktiviert werden.
Zuletzt möchte ich noch auf die Automatic Database Optimization eingehen. Diese Funktion erkennt Leistungsprobleme, wie beispielsweise eine schlechte Wahl der Ausführungspläne, und benachrichtigt den Administrator. Daneben kann sie versuchen, diese Probleme automatisch zu beheben. Gerade bei großen Datenbanken, deren Ausmaße dafür sorgen, dass eine manuelle Überwachung durch den Administrator nur schwer umsetzbar ist, kann diese Funktion die Arbeit des Administrators erleichtern. Sie kann mit dem folgenden Befehl aktiviert werden:
ALTER DATABASE [DBName] SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );Weitere Neuerungen sind Stretched Databases, also die Auslagerung von kalten Daten in die Azure Cloud, die erstmalige Unterstützung von Linux als Betriebssystem, eine neue Versionen des SQL Server Management Studios (17.x), sowie die Möglichkeit, ein graphenorientiertes Datenbankschema zu verwenden. Das graphenorientiere Schema hat zwar den gleichen Funktionsumfang wie das relationale Schema, jedoch kann der Einsatz dieses Schemas unter Umständen bei hierarichischen Datensätzen zu einer performanteren Ausführung von Queries führen.
[1] https://docs.microsoft.com/de-de/sql/relational-databases/performance/adaptive-query-processing
MEHR BLOG-KATEGORIEN
- ASP.NET
- Active Directory
- Administration Tools
- Allgemein
- Backup
- ChatBots
- Configuration Manager
- DNS
- Data Protection Manager
- Deployment
- Endpoint Protection
- Exchange Server
- Gruppenrichtlinien
- Hyper-V
- Intune
- Konferenz
- Künstliche Intelligenz
- Linux
- Microsoft Office
- Microsoft Teams
- Office 365
- Office Web App Server
- Powershell
- Remote Desktop Server
- Remote Server
- SQL Server
- Sharepoint Server
- Sicherheit
- System Center
- Training
- Verschlüsselung
- Virtual Machine Manager
- Visual Studio
- WSUS
- Windows 10
- Windows 8
- Windows Azure
- Windows Client
- Windows Server
- Windows Server 2012
- Windows Server 2012R2
- Windows Server 2016
- Windows Server 2019
- Windows Server 2022
- Zertifikate








