

Migration SCOM zu Azure Monitor
Viele Unternehmen nutzen zur Überwachung Ihrer Umgebung den System Center Operations Manager. Oft aber werden nicht alle Funktionen dessen genutzt oder benötigt.
Für den Fall, dass nur Metriken und Log-Einträge überwacht werden müssen und die Administratoren über auffällige Merkmale informiert werden möchten, gibt es auch eine alternative Methode: den Umzug in die Cloud mit Azure Monitor.
Mit der Strategie Microsofts, mehr und mehr Dienste in die Cloud zu verlegen, ergeben sich für IT-Administratoren viele Vorteile: durchgehende Verfügbarkeit, Abrechnung nach Verbrauch, einfache Skalierung, etc…
In diesem Sinne ist es selbstverständlich, auch bei Diensten wie der Überwachung der eigenen Umgebung über einen Umzug in die Cloud nachzudenken.
In dieser Blog-Serie untersuchen wir, was Azure Monitor eigentlich ist, wie wir die Überwachung unserer Umgebung durch Azure einrichten können, wie wir Regeln aus SCOM zu Azure übertragen können und sehen uns Beispiele für wichtige Regeln an.
Was ist Azure Monitor?
Azure Monitor ist eine einheitliche Lösung innerhalb der Azure Cloud, die das Sammeln, Analysieren und Überwachen von Daten an einer zentralen Stelle sammelt. Sie können Diagramme erstellen, Warnungsregeln für Anomalien definieren und komplexe Anfragen beschreiben und ausführen.
Azure Monitor ist dabei keine Ressource, die Sie erstellen und bezahlen müssen. Es ist mehr ein zentraler Dienst in Azure, um die Arbeit der Überwachung zu erleichtern.
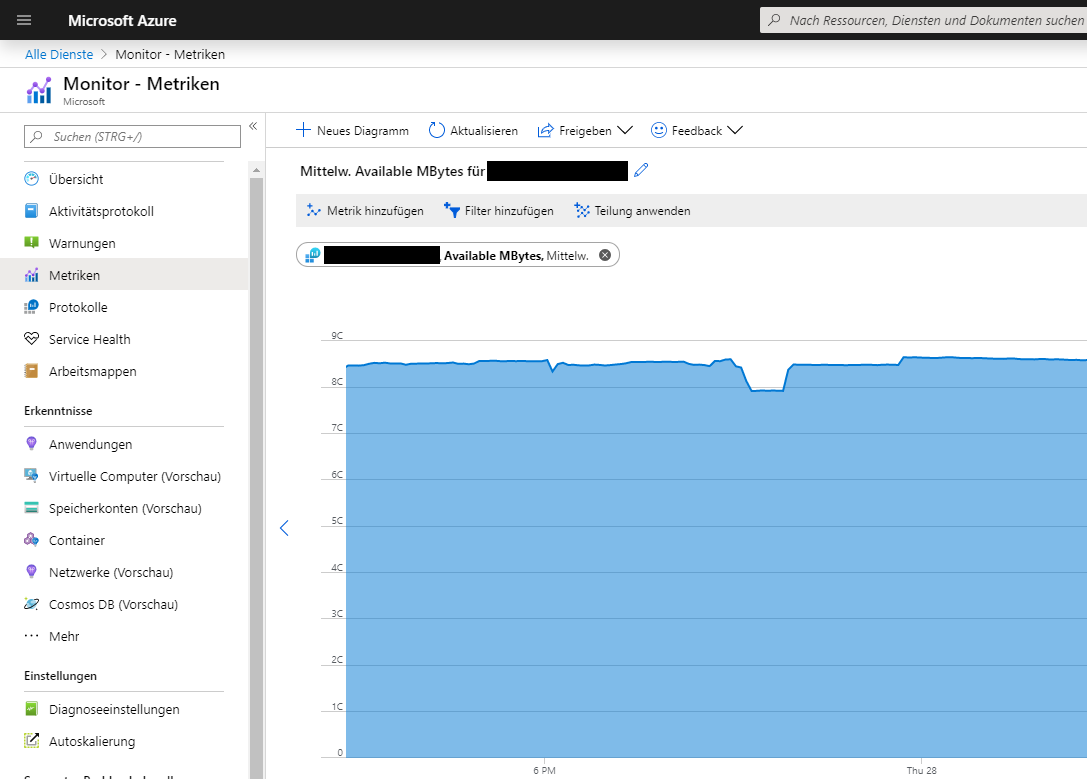
Daten in Azure Monitor
Azure Monitor unterscheidet dabei zwei Arten von Daten:
Metriken (wie etwa CPU-Auslastung, http 4xx Fehlerzahl, Antwortzeiten, …)
Metriken sind numerische Werte, die in festen Zeitabschnitten erfasst werden. Allein genommen sind diese reinen Daten und sagen ohne eine zeitabhängige Analyse noch nichts über Fehler aus. Sie können quantitativ ausgewertet werden.Protokolle (wie Ereignisprotokolle, Aktivitäts-Logs, IIS Logs, …)
Protokolle sind qualitative Daten. Einträge sind auf der einen Seite zeitlich sehr variabel und können auf der anderen Seite nicht automatisch ausgewertet werden. Über Metadaten und Inhalt können aber trotzdem komplexe Anfragen gestellt werden.
Die Daten von allen Ressourcen in Azure werden dabei automatisch erfasst und sind ohne Konfiguration in Azure Monitor verfügbar. Externe Datenquellen (wie eine lokale Umgebung) lassen sich aber ebenfalls leicht anbinden.
Warnungsregeln in Azure Monitor
Sobald die Daten in Azure Monitor vorhanden sind, können Warnungsregeln (Alerts) zur Überwachung der Daten eingerichtet werden. Regeln führen dabei im Hintergrund ständig Anfragen aus und können beliebige Aktionen ausführen, sobald die Anfrage erfüllt ist.
Diesen Regeln werden wir uns im späteren Teil „Häufig genutzte Regeln“ genauer widmen.
Beispiel: Überwache die CPU-Auslastung einer Reihe von VMs in Azure und schicke den Administratoren eine E-Mail zu, sobald diese Auslastung über einen Zeitraum von 10 Minuten 80% überschreitet.
Azure Monitor bietet darüber hinaus viele weitere Funktionen an, auf die wir aus Platzgründen hier aber nicht eingehen werden. Für Interessierte können wir deshalb die offizielle Dokumentation von Azure Monitor empfehlen.
Meine Umgebung mit Azure Monitor verbinden
Wer bereits SCOM im Einsatz hat, hat es einfach mit dem Umstieg zu Azure Monitor: Der gleiche Microsoft Monitoring Agent (MMA), der Daten zu einer SCOM-Instanz sendet, kann auch mit Azure verbunden werden.
Log Analytics Arbeitsbereich einrichten
Als Datensenke in Azure dient ein Log Analytics Arbeitsbereich (Log Analytics Workspace). Das ist eine Azure Ressource, die den Empfang und die Speicherung von empfangenen Metriken und Protokollen übernimmt, ähnlich einer Datenbank.
Zuerst müssen wir deshalb in Azure einen Log Analytics Arbeitsbereich erstellen. Darin öffnen wir den Reiter „Erweiterte Einstellungen“ (bzw. „Advanced Settings“) und speichern uns dort die Workspace ID und den Primary Key. Diese Informationen brauchen wir, um MMAs mit Azure zu verbinden. Und bei Bedarf kann dieser MMA auch direkt hier heruntergeladen werden.

MMA konfigurieren
Nun müssen wir auf jedem Computer, auf dem der Agent installiert ist, die Verbindung zu Azure einrichten. Dazu öffnen wir die Systemsteuerung und öffnen den Eintrag „Microsoft Monitoring Agent“ (eventuell muss dazu die Ansicht auf Symbole statt Kategorien umgestellt werden).
Im neuen Fenster sollte es einen Reiter „Azure Log Analytics“ geben. Falls nicht, muss eine neuere Version des MMA installiert werden. Hier kann dann die Verbindung zu Azure Monitor mithilfe der Workspace ID und des Primary Key (s. o.) eingerichtet werden. Eine weitere Konfiguration ist nicht nötig und die exakte Auswahl der erfassten Daten wird in Azure und nicht auf den Computern selbst gewählt.
Für den Übergang kann übrigens sowohl der SCOM als auch Azure Monitor parallel betrieben werden, indem beide Verbindungen innerhalb des MMA konfiguriert sind. Beim Entfernen des Computers aus SCOM wird dann auch nur die SCOM-Verbindung getrennt, Agent und Azure-Verbindung bleiben aber bestehen.
Hinweis: Um die manuell wiederholte Installation und Konfiguration von MMA zu vermeiden, kann dieser auch per Kommandozeile und damit per GPO installiert werden. Mehr Informationen finden sich hierzu in der Dokumentation „Verbinden von Windows-Computern mit Azure Monitor“.
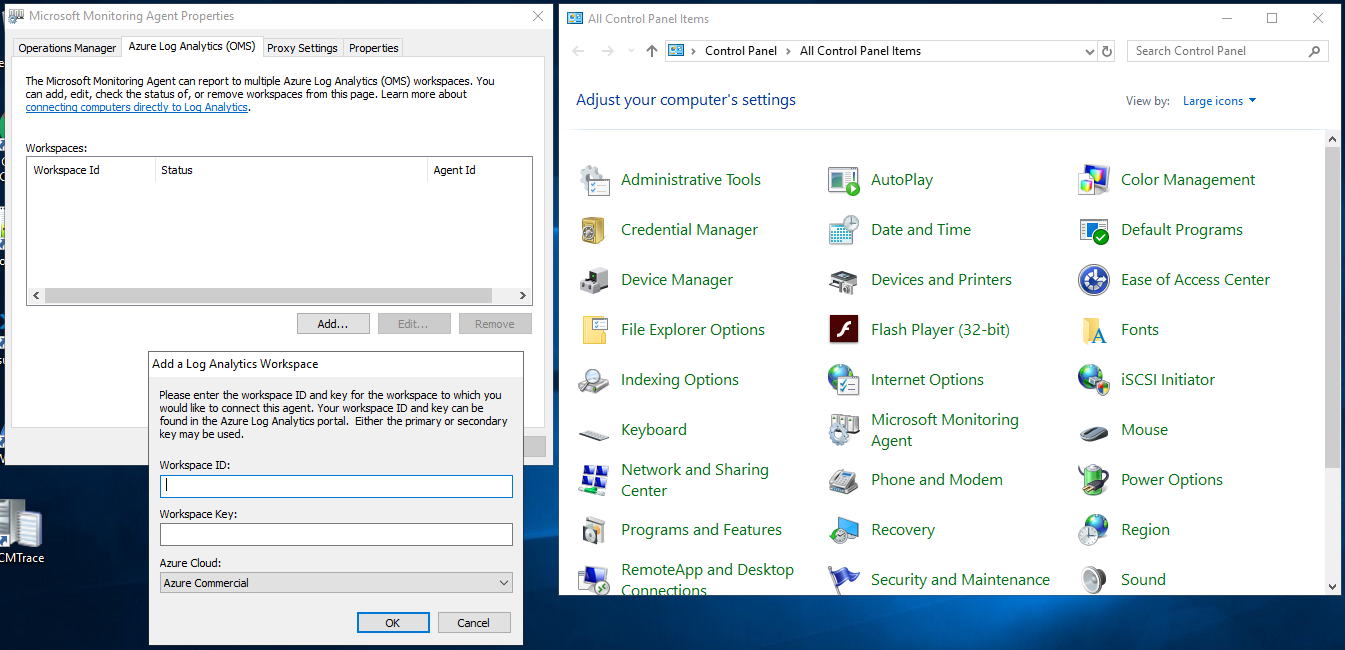
Erfasste Daten definieren
Azure Monitor erfasst von On-Premise PCs und VMs verschiedene Arten von Daten. Hierbei handelt es sich um Metriken – in Form von Windows-Leistungsindikatoren – sowie um Protokolle, direkt aus dem Windows-Ereignisprotokoll.
Zurück in den erweiterten Einstellungen des Log Analytics Arbeitsbereichen in Azure wählen wir dazu den Reiter „Data“, um die zu erfassenden Daten auszuwählen. Bei beiden Arten von Windows-Daten müssen wir dabei manuell definieren, wie die zu erfassenden Daten heißen, z.B. die Ereignisprotokolle „System“ und „Application“.
Die Windows-Leistungsindikatoren vereinfachen uns eine erste Auswahl. Beim ersten Bearbeiten bekommen wir direkt vorgeschlagen, häufig genutzte Indikatoren mit einem Knopfdruck hinzuzufügen.
Änderungen an diesen Einstellungen müssen dann noch mit einem Klick auf „Save“ gespeichert werden und Azure benachrichtigt dann von selbst alle verbundenen Agenten über die zu sendenden Daten.
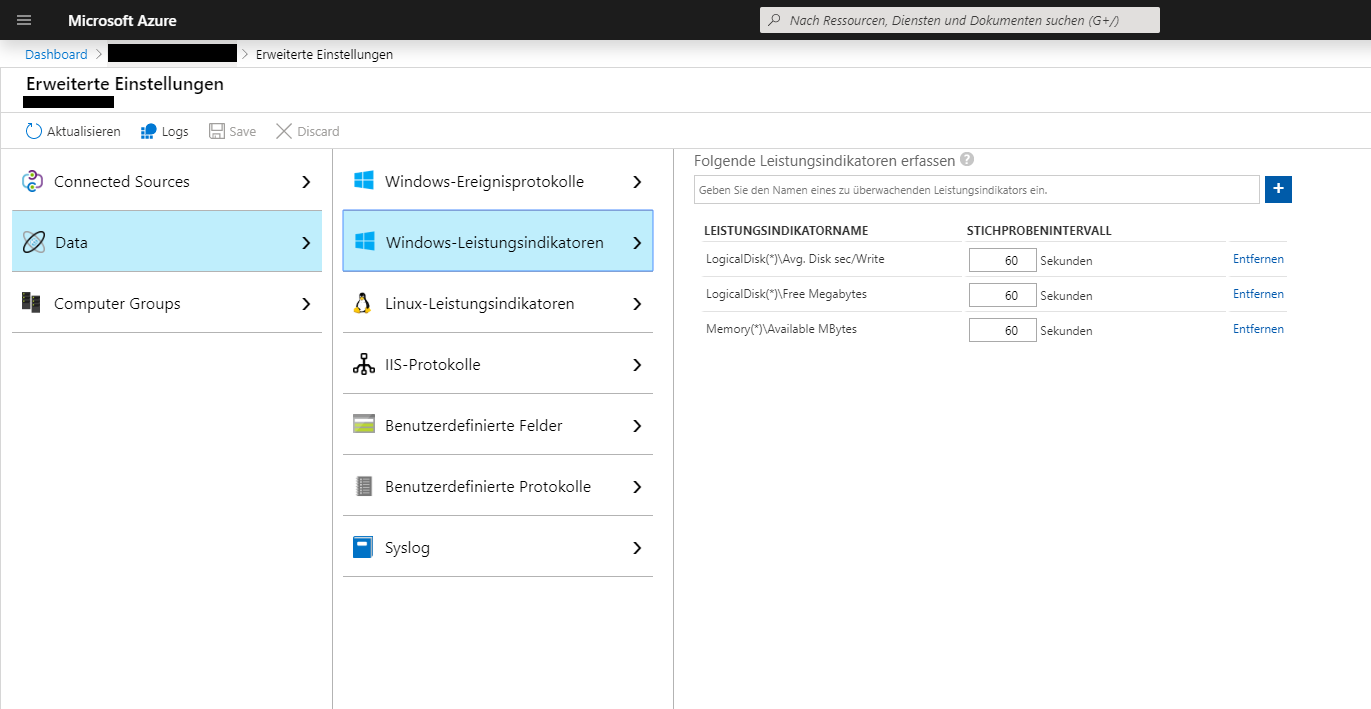
Hinweis zu den Quellen: Wie an den Reitern sichtbar ist, sind Windows-Ereignisprotokolle und Windows-Leistungsindikatoren natürlich nur ein paar der möglichen Datenquellen. Mit „Syslog“ und „Linux-Leistungsindikatoren“ können auch Linux-Betriebssystemdaten erfasst oder mit „Benutzerdefinierte Protokolle“ eigens definierte Protokollquellen eingerichtet werden.
Hinweis zu den Kosten: Log Analytics Arbeitsbereiche werden primär nicht nach Speicherplatz, sondern nach Dateneingangsmenge und Datenaufbewahrungsdauer abgerechnet. Die Standard-Aufbewahrung von 30 Tagen sind kostenlos, alles über diese Länge hinaus kostet extra. Bei der Eingangsmenge hingegen wird mit einem festen Preis pro 2.522 € pro GB (Stand Nov. 2019) abgerechnet. Hier wird deshalb empfohlen, nur die wirklich benötigten Daten zu erfassen und alles andere auszustellen, wie etwa Information-Level-Protokolle oder nicht genutzte Leistungsindikatoren. Die Sektion „Nutzung und geschätzte Kosten“ in der Log Analytics-Ressource hilft, den Datenumfang und dessen Kosten zu überwachen.
Warnungsregeln in Azure definieren
Warnungsregeln (Alerts) lassen sich in und für jede Ressource in Azure definieren. Sie haben die volle Kontrolle darüber, wann eine Warnung ausgelöst wird und was in diesem Fall passiert.
In den Warnungsregeln wird eingestellt, wie häufig diese ausgeführt werden sollen. Bei jeder Ausführung wird die Regel dann überprüft und bei Bedarf eine Warnung ausgesendet. Diese Warnungen sind dabei eigene Objekte, d.h. diese enthalten einen Auslösezeitpunkt, sowie einen Zustand, mit dem ein Administrator verfolgen kann, ob diese Warnung neu, bestätigt oder geschlossen ist.
Hier wird auch zwischen Metrik-Warnungen und Protokoll-Warnungen unterschieden. Bei Metrik-Warnungen kann Azure selbst erkennen, ob eine Warnung bei einer späteren Ausführung wieder behoben ist und setzt die Warnung dann von selbst auf Gelöst. Protokoll-Warnungen hingegen sind alle unabhängig voneinander, sodass die gleiche Regel mehrfach hintereinander neue Warnungen aussenden kann, solange das Problem bei der nächsten Ausführung weiterhin besteht.

Eine neue Regel erstellen
Jede Ressource in Azure hat in ihrer Menüleiste einen eigenen Eintrag „Warnungen“, über den wir neue Regeln für diese Ressource erstellen können. Es geht aber auch zentral über Azure Monitor und dessen Eintrag „Warnungen“ > „Neue Warnungsregel“.
Warnungen bestehen dabei aus 3 Konfigurationen sowie einigen grundlegenden Daten wie Name und Beschreibung: (Betroffene) Ressource, Bedingung, Aktionen.

Bei „Ressource“ wählen wir die Datenquelle aus, in unserem Fall etwa den ersten Log Analytics Arbeitsbereich.
Bei „Bedingung“ wählen wir die konkrete Regel, die beschreibt, ab wann eine Anomalie vorliegt. Wenn wir auf „Hinzufügen“ klicken, bekommen wir eine Liste aller Signale, die wir für die Regeln heranziehen können. Dazu gehören alle Metriken sowie Logs, die wir leicht filtern oder nach einem bestimmten Namen suchen können. Wählen wir z.B. „Free Megabytes“ zum Messen des freien Festplattenspeichers.
Die exakte Konfiguration der Signallogik ist dabei etwas komplex und vom Signaltyp abhängig. Für Metriken sehen wir hier eine Grafik der letzten Stunden, können darunter etwa nach den zu überwachenden Computern filtern und bestimmen letztendlich den Schwellenwert und die Auswertungsbasis.
Vor allem die Gruppierung und Filterung nach Computer ist für unseren Anwendungsfall sehr wichtig. Wir wollen ja bei einer Warnung genau wissen, welcher Computer diese ausgelöst hat und wählen hier deshalb alle vorhandenen Computer aus der Liste aus. Wir können auch das „* auswählen“-Feld rechts aktivieren, damit automatisch alle Computer überwacht werden und auch neu hinzugefügte Computer immer automatisch die Regel übernehmen. Alternativ können wir in der Liste einzelne Computer auslassen, falls etwa manche Regeln nur für manche Computer relevant sind.

Schwellenwert und Ausführungsbasis können wir dabei recht genau angeben. Im Beispiel etwa habe ich eingestellt, dass eine Warnung ab einem Durchschnittswert von unter 5000 MB ausgelöst werden soll. Diese Regel wird dabei jede Minute ausgewertet (Häufigkeit) und nutzt für die Berechnung die Daten der letzten 5 Minuten (Granularität).

Bei „Aktionen“ können wir dann schlussendlich noch auswählen, was geschehen soll, wenn eine Warnung ausgelöst wird. Dies erfolgt durch die Definition einer Aktionsgruppe, die wir auch in anderen Regeln wiederbenutzen können.
Eine Aktionsgruppe kann dabei mehrere verschiedene Aktionen ausführen. Uns stehen dabei sowohl Benachrichtigungen wie E-Mail und SMS, aber auch Nachrichten an automatisierte Systeme wie durch Webhook oder eine Azure Function zur Verfügung. Eine sehr beliebte Aktionsgruppe wäre dabei, einfach dem Administrator eine E-Mail zuzusenden.
Zu guter Letzt wählen wir noch einen Namen sowie einen Schweregrad. Die Schweregrade helfen, die Bedeutung der Warnung zu unterscheiden und orientieren sich an den Schweregraden der Windows Events, von 0 – Kritisch bis 4 – Ausführlich. Und ein Hinweis noch zum Namen: Dieser sollte gut gewählt werden, denn er kann als einziger Teil einer Regeldefinition nicht später geändert werden.
Speichern Sie die Regel und schon wird diese aktiv im Hintergrund laufen. Bezahlt wird dabei ausschließlich für die passive Überwachung durch die Regel. Der Preis hängt nur von der Komplexität der Bedingung ab und nicht von der Anzahl tatsächlich ausgelöster Warnungen. Hier wird Ihnen Azure aber schon bei Definition der Regel einen geschätzten Preis nennen.
SCOM-Regeln in Azure übertragen
Allem voran eine schlechte Nachricht: Es gibt keine direkte Möglichkeit, SCOM-Monitore und -Regeln zu Azure Monitor zu migrieren. Stattdessen muss jede gewünschte Überwachung von Hand neu erstellt werden.
Auf der anderen Seite aber hat das den Vorteil, dass man sich noch einmal vor Augen führen kann, was genau wie überwacht wird. Tatsächlich sind in SCOM häufig viel mehr Regeln konfiguriert (speziell durch viele Management Packs), die nicht unbedingt wichtig oder relevant sind.
Wir wollen nun beispielhaft die SCOM-Regel zur Überwachung der Festplattengeschwindigkeit in Azure Monitor übertragen. Dazu müssen wir wie folgt vorgehen:
Exakte Regeldefinition herausfinden
Benötigte Daten in Azure sammeln
Regel in Azure definieren
1. Exakte Regeldefinition herausfinden
Die System Center Management Packs enthalten fast immer einen Management Pack Guide. So ist z.B. beim “Microsoft System Center Management Pack for Windows Server Operating System 2016” die Datei “Management Pack Guide for Windows Server 2016“ enthalten.
Diese enthält genau wie wir es wollen eine Auflistung der Regeln, eine Beschreibung der überwachten Elemente und die genauen Schwellwerte, ab der Warnungen ausgelöst werden.
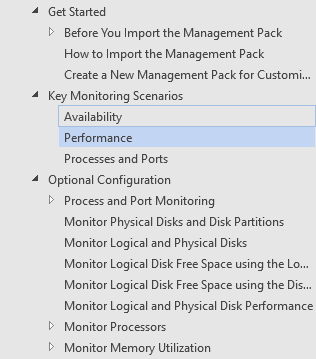
Daten zur Festplattenperformanz finden wir dabei in der Navigation unter „Optional Configuration“ > „Monitor Logical and Physical Disk Performance“. Hier finden wir heraus, dass eine Warnung ausgelöst wird, wenn die durchschnittlichen Sekunden pro Disk-Transfer über eine Spanne von 15 Messungen (= 15 Minuten) über dem Wert .04 liegen.

Daraus ergibt sich die folgende Regel:
Signal: Average Disk Sec./Transfer
Operator: Größer als
Aggregationstyp: Minimum
Schwellenwert: 0.04
Granularität: 15 Minuten
2. Benötigte Daten in Azure sammeln
Gehen wir nun ins Azure-Portal und zu den erweiterten Einstellungen unseres Log Analytics-Arbeitsbereichs, in dem wir die empfangenen Daten konfiguriert haben (siehe Teil „Meine Umgebung mit Azure Monitor verbinden“).

Das von uns gesuchte Signal ist ein Windows-Leistungsindikator und heißt „LogicalDisk(*)\Avg. Disk Sec./Transfer”. Die Suche schlägt uns direkt passende Indikatoren vor, wenn wir z.B. nach „Transfer“ suchen, da die Indikatoren in SCOM und Azure Monitor nicht immer exakt identisch heißen. Als Häufigkeit können wir 60 Sekunden einstellen, da auch SCOM diese Daten nur jede Minute abgreift. Hier denken wir dran, dass wir nach Dateneingang bezahlen, d.h. seltenere Erfassung bedeutet geringere Kosten.
3. Regel in Azure definieren
Direkt nach der Konfiguration können wir uns die neu erfassten Daten noch nicht ansehen. Die MMAs senden nämlich nur neue Daten hoch, was bedeutet, dass die Erfassung erst mit der Konfiguration im letzten Schritt beginnt. Wenn wir Azure nun eine halbe Stunde Zeit geben würden, würden sich einige historische Daten in Azure sammeln, die uns helfen, die Daten bei der Regeldefinition zu visualisieren.
Wir beginnen nun, wie im letzten Teil „Warnungsregeln in Azure definieren“ eine neue Regel für unseren Log Analytics-Arbeitsbereich zu definieren. Als Signal wählen wir den neuen Indikator „Avg. Disk Sec./Transfer“ und gruppieren anhand der Computer, die wir alle per „* auswählen“ in unsere Filterliste mit aufnehmen.

Die Warnungslogik selbst können wir ohne Änderung von SCOM übernehmen. Als Häufigkeit sollte dabei immer ein Wert genommen werden, der gleich oder kleiner als die Granularität ist. Für uns sollte „Alle 15 Minuten“ ausreichen.

Nun wählen wir eine Aktion (wie etwa der Versand einer E-Mail), einen Namen (wie etwa „Disk Slow“) und einen Schweregrad (wie etwa „2“ = Warnung).
Damit wäre die Regel erstellt und wir können uns daran machen, die nächste zu übertragen.
Hinweis zu Protokollen als Signal
Das Beispiel oben zeigt den Prozess für eine Metrik-Regel. Bei Protokollregeln sieht das etwas anders aus, da nicht mit numerischen Daten gearbeitet wird.
Stattdessen definieren wir Azure Protokollabfragen. Diese sind eine Art der Datenbankabfrage, die sich stark an der Syntax und Benutzung von PowerShell anlehnt. Eine genaue Beschreibung ist auch hier in der Azure Dokumentation zu finden.
Mit diesen Protokollanfragen suchen wir dann in den Protokollen nach konkreten Einträgen, entweder anhand des Inhalts, der Quelle, der EventID oder gänzlich anderer Daten. Wir können diese mit der Anfragensprache auch gruppieren, filtern, zeitlich begrenzen oder umwandeln.
Protokollregeln verwenden im Kern solch eine Abfrage, die regelmäßig ausgeführt wird. Als Signal wählen wir dazu „Custom log search“. Die Warnungslogik wiederum agiert nach Wahl entweder nach der Anzahl der resultierenden Ergebnisse oder nach einem numerischen Wert, der im Abfrageergebnis (unter dem Namen „AggregatedValue“) vorkommt.
Als Beispiel könnten wir anhand der EventID nach einem konkreten Protokolleintrag suchen und eine Warnung verschicken, sobald dieser in den Protokollen eines unserer PCs auftaucht.
Bevor die Regel aktiviert wird, müssen wir zusätzlich daran denken, auch Protokolle in Azure zum Empfang zu konfigurieren. Hier geschieht das aber über die Einstellung „Windows-Ereignisprotokolle“ in den erweiterten Einstellungen, der wir den Namen des Protokolls geben müssen.
Häufig genutzte Regeln
Wer SCOM noch nicht oder noch wenig genutzt hat oder aber gar nicht weiß, welche der vielen Regeln überhaupt tatsächlich hilfreich sind, wird sich schnell fragen, was empfohlen wird.
Eine Suche danach ist aber leider vergebens. Soweit gibt es weder von Microsoft noch externen Firmen konkrete Empfehlungen, welche Regeln zur Grundüberwachung einer Umgebung von Bedeutung sind. Dafür sind die Anforderungen viel zu groß und speziell in Azure, wo pro Regel bezahlt wird, wollen wir nicht unnötige Regeln anhäufen, die uns keinen Mehrwert bieten.
Aus diesem Grund wollen wir an dieser Stelle einige Regeln beispielhaft aufzählen, die zeigen, was mit Azure Monitor überwacht werden kann. Gerne können diese als Inspiration dienen, um Ihnen eine Richtung für passende Regeln zu geben.
Beispiel 1: Niedriger Arbeitsspeicher
Bei zu großer Auslastung des Arbeitsspeichers kann sich die Arbeitsgeschwindigkeit signifikant verringern, ohne dass das Problem durch direkte Fehler auftritt. Schwellenwert und Regelhäufigkeit sind hier stark von der gewünschten Art und Häufigkeit der Überwachung abhängig.
Benötigte Daten: “Memory(*)\Available MBytes” (Windows-Leistungsindikator)
Signal: Available MBytes
Warnungslogik: Maximum kleiner als 2.5
Granularität: 5 Minuten (je nach Bedarf)
Häufigkeit: alle 5 Minuten (je nach Bedarf)
Beispiel 2: Niedriger Festplattenspeicher
Bei zu niedrigem Festplattenspeicher können Operationen auf dieser fehlschlagen und damit wichtige Programme und Funktionen in ihrer Ausführung gestört werden.
Benötigte Daten: “LogicalDisk(*)\Free Megabytes” (Windows-Leistungsindikator)
Signal: Free Megabytes
Warnungslogik: Mittelwert kleiner als 500
Granularität: 5 Minuten (je nach Bedarf)
Häufigkeit: alle 5 Minuten (je nach Bedarf)
Beispiel 3: Unerwartetes Herunterfahren eines PCs
Bei jedem Herunterfahren eines PCs (bzw. bei dessen Neustart) wird in den Windows-Ereignisprotokollen erfasst, ob dieser geplant, beabsichtigt oder unerwartet war. Für ein unerwartetes Herunterfahren stehen dabei Ereignisse mit den IDs 1001, 6008 und 41 im „System“-Protokoll.
Benötige Daten: „System“-Protokoll (Windows-Ereignisprotokolle)
Signal: Custom log search
Abfrage:
Event
| where EventLog == "System" and (EventID == 1001 or EventID == 6008 or EventID == 41)
| summarize AggregatedValue = count() by bin(TimeGenerated, 5m), Computer
| sort by TimeGenerated descWarnungslogik: Metrische Maßeinheit größer als 0
Auslösen basierend auf: Sicherheitsverletzungen gesamt größer als 0
Aggregieren nach: Computer
Zeitraum: 15 Minuten (je nach Bedarf)
Häufigkeit: alle 15 Minuten (je nach Bedarf)
Beispiel 4: Auslaufende Zertifikate
Als Beispiel für Abfragen aus zusätzlichen Protokollen eignet sich das drohende Auslaufen eines Zertifikats. Dreimal täglich überprüft Windows die lokal installierten Zertifikate auf Gültigkeit und schreibt einen Protokolleintrag in das Protokoll „Application“, wenn das Ablaufdatum innerhalb der nächsten 10 Wochen liegt.
Benötige Daten: „Application“-Protokoll (Windows-Ereignisprotokolle)
Signal: Custom log search
Abfrage:
Event
| where Source == "Microsoft-Windows-CertificateServicesClient-AutoEnrollment" and EventID == 64
| summarize AggregatedValue = count() by bin(TimeGenerated, 5m), ComputerWarnungslogik: Metrische Maßeinheit größer als 0
Auslösen basierend auf: Sicherheitsverletzungen gesamt größer als 0
Aggregieren nach: Computer
Zeitraum: 1440 Minuten (je nach Bedarf)
Häufigkeit: alle 1440 Minuten (je nach Bedarf)
MEHR BLOG-KATEGORIEN
- ASP.NET
- Active Directory
- Administration Tools
- Allgemein
- Backup
- ChatBots
- Configuration Manager
- DNS
- Data Protection Manager
- Deployment
- Endpoint Protection
- Exchange Server
- Gruppenrichtlinien
- Hyper-V
- Intune
- Konferenz
- Künstliche Intelligenz
- Linux
- Microsoft Office
- Microsoft Teams
- Office 365
- Office Web App Server
- Powershell
- Remote Desktop Server
- Remote Server
- SQL Server
- Sharepoint Server
- Sicherheit
- System Center
- Training
- Verschlüsselung
- Virtual Machine Manager
- Visual Studio
- WSUS
- Windows 10
- Windows 8
- Windows Azure
- Windows Client
- Windows Server
- Windows Server 2012
- Windows Server 2012R2
- Windows Server 2016
- Windows Server 2019
- Windows Server 2022
- Zertifikate











